분산 시스템에서 ID를 만들 때 아래 조건을 만족해야 된다고 생각해보겠습니다
- 유일해야 함
- 정렬 가능해야 함 -> 시간의 흐름에 따라 커지는 값이다
- 항상 1씩 증가하는지는 중요하지 않으며, 아침에 만든 ID보다 저녁에 만든 ID가 크면 되는 수준
- 64비트로 표현될 수 있는 숫자값(numeric value)이어야 함
- 초당 1만개가량 생성할 수 있어야 함
#1 auto_increment 사용
RDBMS에서 가장 간단하게 떠올릴 수 있겠지만, 운영환경 서비스에서 db를 한 대만 쓰는 경우는 많지 않을거라 현실적이진 않습니다
#2 multi-master replication

#1과 동일하게 RDBMS의 auto_increment 기능을 쓰지만, 대신 다음 ID를 구할 때마다 1씩 증가시키는게 아니라, 전체 DB 서버의 수만큼 증가시킵니다.
유일성은 보장되지만 시간 흐름에 맞춰 커지도록 할 수 없으며(예를 들어 위 그림에서 id=9999, 10 사이 시간의 대소 비교 불가), db서버 추가/삭제도 어렵습니다.
#3 UUID
uuid는 충돌 확률이 매우 낮은 id 형식입니다. 128비트 값이며, '7e7490f7-7bf5-4dfc-b6a8-3f15db4881cd' 같은 형태를 갖습니다.
uuid 값은 랜덤한 값입니다 (v4 기준)

서버간 조율이 필요하지 않으니, 동기화 이슈가 없습니다
하지만 uuid는 128비트이고, 요구사항이 64비트라서 요구사항을 만족하지 못합니다
또한 id가 숫자값이 아니고, 랜덤 값이라 시간순 정렬이 불가능합니다.
#4 티켓서버

ID 생성기 서버, 일명 티켓서버를 만드는 방법이 있습니다.
DBMS의 auto_increment 기능만 가진 독립적인 서버를 만든다 생각하시면 되는데, 구현은 쉽지만 단일 장애점(SPOF, Single Point of Failure)이 됩니다. 또 티켓 서버를 여러대 둬서 SPOF를 회피하고자 하면 데이터 동기화 문제가 다시 생깁니다.
Flickr가 이 방식을 쓰고 있습니다 (https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/)
#5 Snowflake by twitter
(https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake)
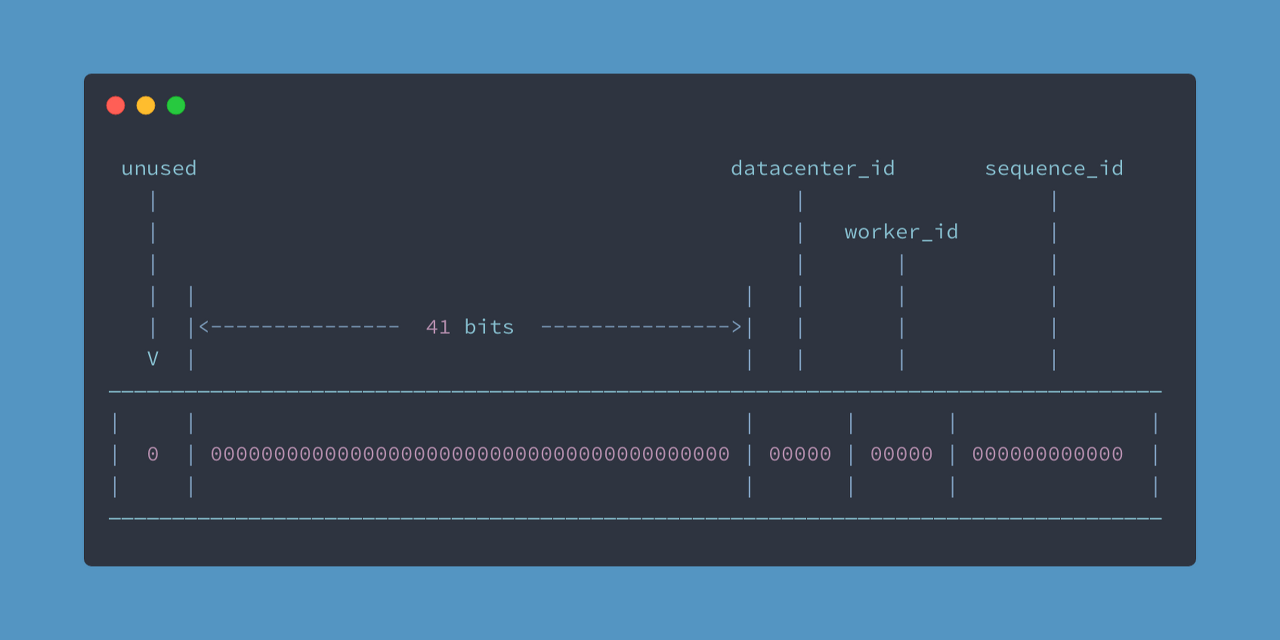
트위터가 쓰고 있는 방식입니다
64비트 중, 41비트를 타임스탬프(epoch 이후 경과한 ms), 나머지는 데이터센터 id, 서버 id, sequence, reserved 비트로 구성한 형태입니다.
epoch 이후 2^41 milliseconds = 약 70년을 사용할 수 있는 시스템이고, 동기화 없이 각 서버에서 자체적으로 계산이 가능합니다
문제는 데이터센터 id, 서버 id 변경이 잘못되면 충돌이 생길 수 있다는 것과, 언젠가는 타임스탬프가 고갈돼 epoch를 바꾸거나 다른 ID 포맷으로 마이그레이션이 필요하다는 점 정도가 있겠습니다.
또한 시퀀스 id가 12비트라, 1ms에 2^12=4096개 이상 ID가 생성될 수 있다면 충돌이 생깁니다.
Reference
- 가상 면접사례로 배우는 대규모 시스템 설계 기초