Coursera - Supervised Machine Learning: Regression and Classification (2주차)
Supervised Machine Learning: Regression and Classification
Learn Machine Learning from Stanford University. Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, ...
www.coursera.org
Multiple Linear Regression
Multiple features
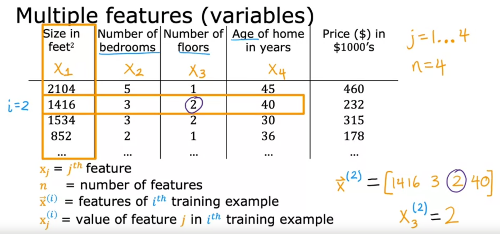
피쳐가 여러개인 경우, 위와 같은 notation 사용
한 input을 row vector라고도 부르고, vector임을 강조하기 위해 변수 위에 화살표를 그리기도 함

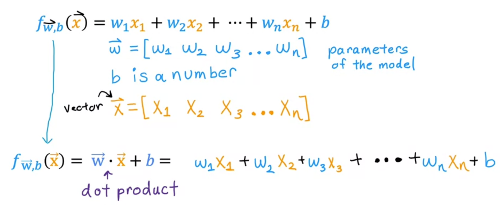
모델은 "두 벡터의 내적(inner product) + b(상수)"로 표현할 수 있다
(Multivariate regression은 다른걸 의미하기 때문에, "multiple linear regression"이라 부르겠음)
-> vectorization
Vectorization

ex) 내적 -> dot product 메소드를 쓰면 f = np.dot(w, x) + b 이렇게 깔끔
벡터화(Vectorization) 장점
- 코드가 간결
- 최적화 (NumPy 내부적으로 행렬계산을 병렬처리로 최적화함)

모종의 방식으로 병렬로 쭉 뿌려서 계산하고 취합 (cuda 등)

Gradient descent를 vector notation으로 바꾸면 위와 같다
Alternative to gradient descent: Normal equation(정규방정식)
- 특징
- Linear regression에서만 사용
- w, b를 iteration 없이 찾음
- 단점
- 다른 learning algorithm에 적용 불가 (ex. logistic regression algorithm, neural network, ...)
- 피처가 많으면 느려짐(ex. >10000)
라이브러리에 Gradient descent와 Normal Equation이 둘다 지원되는 경우, 보통은 Gradient descent가 recommended method임
Gradient Descent in practice
Feature Scaling
피쳐마다 값의 범위, 단위가 달라서 특정 피쳐에 편향되는 현상을 해결하기 위한 방법
- 표준화(Standardization): 서로 다른 변수를 일정 분포를 가진 값으로 변환 (ex. 표준정규분포)
-> SVM, Linear Regression 등은 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현되어 있기 때문에
(== Z-score normalization이라고도 함) - 정규화(Normalization): 서로 다른 변수의 크기를 통일하기 위해 특정 범위로 변환 (보통 [0, 1])

위처럼 각 피쳐별 범위가 다르면 수렴에 오래 걸릴 수 있음.

Mean normalization(== min-max normalization)
⚠️ 주의사항: 아웃라이어(Outlier, 이상치)에 큰 영향을 받기 때문에 이상치 제거 후 정규화 필요

Z-Score normalization
가우시안 분포로 정규화
정확히 (0, 1)의 범위로 스케일링 되는 것은 아니지만 아웃라이어의 영향을 크게 받지 않음.

피쳐 범위를 보고 적절히 리스케일링을 해야 함
리스케일링 하는 것은 no harm, 애매하다 싶으면 하면 됨
Checking gradient descent for convergence
Gradient descent를 돌릴 때, 수렴 가능한지 어떻게 파악?

Learning curve를 봤을 때 이런 식으로 cost function J(w, b)가 iteration이 지나감에 따라 점진적으로 줄어드는 모양이 나와야 함
그렇지 않다면 보통 Learning rate가 너무 크거나, 버그가 있거나
몇 iteration만에 수렴하는지는 어플리케이션마다 다르기 때문에 plot을 그려 추이를 보는게 좋다
Automatic convergence test: cost 변화량이 엡실론(ε, 아주 작은 값)보다 작아지면 수렴했다고 판단
Choosing the learning rate
Learning rate가 너무 작으면 수렴(converge)하는데 오래 걸리고, 너무 크면 발산(diverge)함

cost 그래프를 봤을 때
- Fluctuation이 있다 -> 버그 or too large
- 꾸준히 올라간다 -> 버그 (ex. w_i = w_i + alpha*d1 ...)
잘 안되면.. 그냥 알파를 작게 설정할것. 엄청 작게 설정했는데도 꾸준히 cost 올라가면 코드에 버그 있는거

팁) 0.001부터 시작해서 3배씩 늘려가면서 튜닝
Feature Engineering
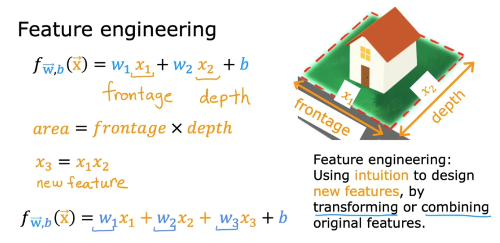
: Using intuition to design new features, by transforming or combining original features
Polynomial Regression

다항회귀: 선형모델 한계 극복
x, x^2, .. 범위가 다르기 때문에 Feature scaling이 중요

sqrt(x)도 하나의 선택이 될 수 있음
어떤 피쳐를 선택해야 할까? -> 다음 코스에서 더 자세히 알아볼 예정
'강의노트' 카테고리의 다른 글
| Coursera - Supervised Machine Learning: Regression and Classification (1주차) (0) | 2022.07.08 |
|---|