Coursera - Supervised Machine Learning: Regression and Classification (1주차)
Supervised Machine Learning: Regression and Classification
In the first course of the Machine Learning Specialization, you will: • Build machine learning models in Python using popular machine learning ... 무료로 등록하십시오.
www.coursera.org
코세라 Andrew Ng 센세의 새 강의를 들으며 필기한 포스트입니다.
지도 vs 비지도 기계학습
기계학습(Machine Learning)이란 무엇인가
"Field of study that gives computers the ability to learn without being explicitly programmed."
명시적으로 프로그래밍하지 않고도 컴퓨터가 학습할 수 있는 능력을 부여하는 연구분야
- Arthur Samuel (1959)
크게는 두가지 유형으로 나뉨
- 지도학습(Supervised Learning): 실세계에서 가장 많이 활용됨
course 1, 2 - 비지도학습(Unsupervised learning)
course 3
(+ Recommender system, Reinforcement learning, ...)
지도학습 (Supervised Learning)

x -> y 매핑을 학습하는 알고리즘
특징은 학습 데이터를 이용해 학습할 수 있다는 것

실제 활용되고 있는 예제들
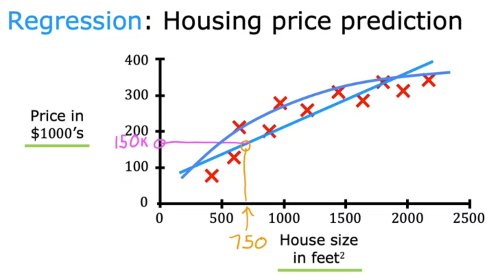
지도학습 예제 - 회귀(Regression): 실수값을 예측 (가능한 output이 무한히 많음)
ex) 집 크기와 가격 사이 데이터를 이용해 학습, 집 크기를 입력하면 가격을 예측 (상관관계의 형태가 직선, 곡선, ... 여러 형태 가능)
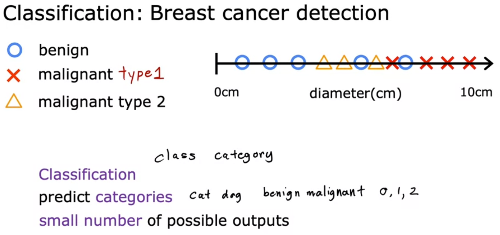
지도학습 예제 - 분류(Classification): 데이터를 여러 값 중 하나로 분류 (가능한 output이 적음)
ex) 유방암 크기에 따른 분류 (양성, 악성, ..)
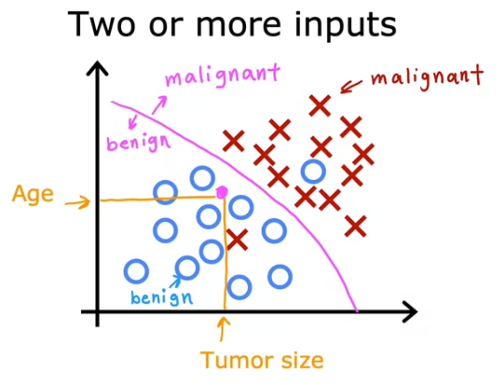
Multiple variable 분류 예제
비지도학습 (Unsupervised Learning)
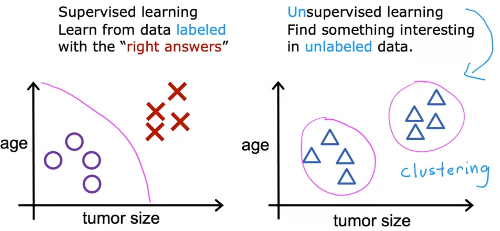
지도학습은 라벨링이 된 학습 데이터를 이용해 학습하는 과정이 필요하지만, 비지도학습은 라벨링 되지 않은 데이터를 이용해 패턴이나 구조 등을 찾는데 사용됨

ex) 구글 뉴스
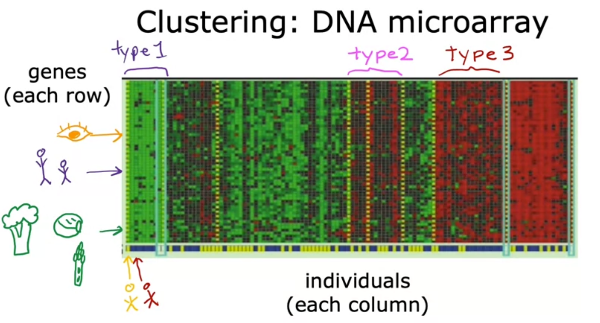
ex) DNA microarray

ex) 고객 그루핑
Clustering
- 이상 탐지(Anomaly detection)
- 차원 축소(Dimensionality Reduction)
회귀 모델 (Regression Model)
선형회귀 (Linear Regression)

x, y 사이 선형함수 모델링하는 방법
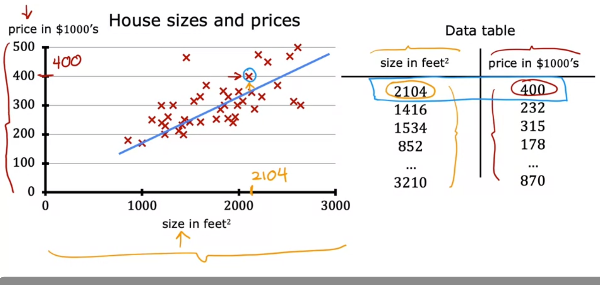
데이터 테이블 예시

표기방법
- x = 입력 변수 or feature(특징)
- y = 출력 변수 or target
- m = 학습 데이터의 개수
- (x, y) = 학습 데이터 하나
- (x^i, y^i) = 학습 데이터의 i번째 예 (not exponent)

학습 데이터(feature, target 쌍)을 learning algorithm이 학습해 모델 생성
- 입력: feature
- 모델: hypothesis, function
- 출력: ŷ(y-hat), prediction, estimated y
\[f_{w, b}(x) = f(x) = wx + b\]
Univariate Linear regression = Linear regression with one variable
Cost Function
Cost Function 공식
\[f_{w, b}(x) = wx + b\]
w,b: parameters (학습 과정에서 모델을 향상시키기 위해 조정되는 값), =coefficients, weights
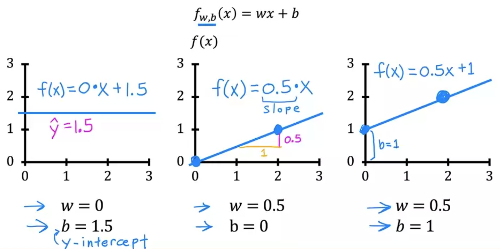
파라미터별 \( f_{w,b}(x) \)의 형태

\[ J(w,b)=\frac{1}{2m} \sum_{i=1}^m \left( \hat y^{(i)} - y^{(i)} \right) ^2 \]
Cost function: Squared error cost function (보편적으로 이용됨. 애플리케이션마다 다른 cost function 사용하는 경우도 존재)
Cost Function Intuition
모델 f(x) = wx+b에서 w, b 파라미터를 변경할 수 있다
cost function J(w, b)를 최소화하는 것이 목적

파라미터 b를 제외하고 생각해보자. w=1에 대해 J(w)는 0이다. 계산은 아까 만든 공식에 predict(\(\ hat y\) ) 값을 집어넣으면 된다.


w를 바꿔가며 J(w)값 계산

여러 w에 대한 J(w)를 계산하며 J(w)를 최소화하는 w 값을 찾을 수 있다
Visualizing the cost function

파라미터 두개가 있으면 3d plot을 이렇게 그릴 수 있다
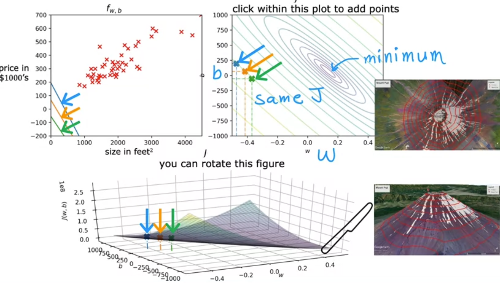
-> 등고선(contour) plot을 만들면 이렇다. 이때 등고선은 같은 cost를 갖는 w, b의 쌍이라 할 수 있다 (위 plot에서 동일한 높이)
눈으로 보고 best fit weight를 고르는 건 한계가 있기 때문에, systematic way 필요 -> gradient descent 등의 알고리즘
Train the model
Gradient Descent (경사하강법)

J(w, b)에 대해 최초 w, b값(보통 0, 0)에서부터 시작해서 J(w, b)가 줄어드는 방향으로 w, b를 계속 변경
언제까지? J(w, b)가 minimum 또는 그 근처까지 올 때까지. (local minimum도 포함)

J(w, b)가 squared error cost가 아닌 경우 보통은 이렇게 나옴. (squared면 이전의 bowl 형태로 나옴)
이때, (w, b) 한 지점에서 시작한다고 했을 때 step size에 따라 다른 local minimum에 도달 가능함 (converge, 수렴)
내려가는 방향은 동일 step size에 가장 많이 내려가는 경로를 선택 -> w, b에 대해 편미분해서 각 축에 대한 기울기 구할 수 있음
구현방법

\( \alpha \) = Learning rate (step size)
매 step마다 w, b를 위 식으로 업데이트 (until convergence, 수렴할 때까지)
⚠️ 주의: w, b를 동시에(simultaneously) 업데이트 해야함
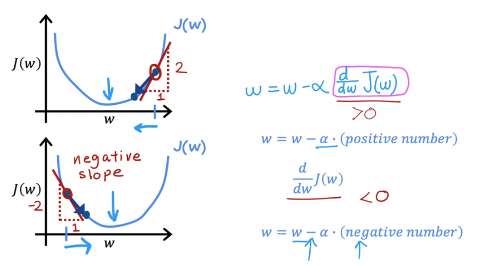
Learning rate는 항상 양수
기울기가 양수라면 w -= alpha * 기울기이므로 w값이 작아지고, 음수인 경우 반대. 즉 어느 지점에서 시작하든 minimum으로 향해 간다.
Learning Rate

Learning rate가 너무 작으면 수렴까지 오래 걸림 (하지만 언젠간 무조건 수렴함)
너무 크면 재수 없으면 발산(diverge)할 수 있음
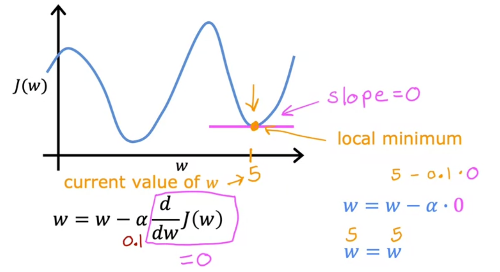
Local minimum에서 시작한 경우 한 step만에 끝남
(Q. global minimum을 얻으려면 어떻게 해야 하는가)
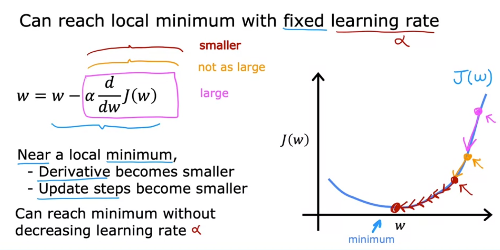
learning rate가 고정된 값이어도 minimum에 도달하면서 점점 기울기도 줄어들어 변화량이 줄어드니 수렴에는 문제가 없음
Gradient descent for Linear Regression

Update step

squared error cost -> global minimum만 존재 (convex function)
Batch gradient descent: 매 step마다 전체 학습 데이터를 사용하는 방식
'강의노트' 카테고리의 다른 글
| Coursera - Supervised Machine Learning: Regression and Classification (2주차) (0) | 2022.07.10 |
|---|